数据库系统概念
| 本文总阅读量次概述
1. 什么是数据库?
数据库管理系统(DataBase-Management System, DBMS)由一个互相关联的数据的集合和一组用以访问这些数据的程序组成。这个数据集通常称为数据库。
数据库结构的基础是数据模型(data model)。数据模型是一个描述数据、数据联系、数据语义以及一致性约束的概念工具的集合。数据模型提供了一种描述物理层、逻辑层以及视图层数据库设计的方式。
数据模型可被划分为四类:
- 关系模型(relational):关系模型用表的集合来表示数据和数据间的联系。
- 实体-联系模型(entity-relationship model):实体-联系(E-R)数据模型给予对现实世界的这样一种认识:现实世界由一组称作实体的基本对象以及这些对象间的联系构成。
- 基于对象的数据模型(object-based data model):面向对象的数据模型可以看成是E-R模型增加封装、方法和对象标识等概念后的扩展。
- 半结构化数据模型(semistructured data model):半结构化数据结构模型允许那些相同类型的数据项含有不同的属性集的数据定义。可扩展标记语言(eXtensible Markup Language, XML)被广泛的用来表示半结构化数据。
2. 数据库语言
数据库操纵语言(Data-manipulationn Language)来表达数据的查询和更新。数据库定义语言(data-definition language)来定义数据库模型。
3. 关系数据库
关系数据库基于关系模型,使用一系列来表达数据以及这些数据之间的联系。
3.1 关系数据库的结构
关系数据库由表的集合构成,每个表有唯一的名字。
一般来说,表中一行代表了一组值之间的一种联系。由于一个表就是这种联系的一个集合,表这个概念和数学上的关系这个概念是密切相关的,这也正是关系数据模型名称的由来。
4. 数据库存储和查询
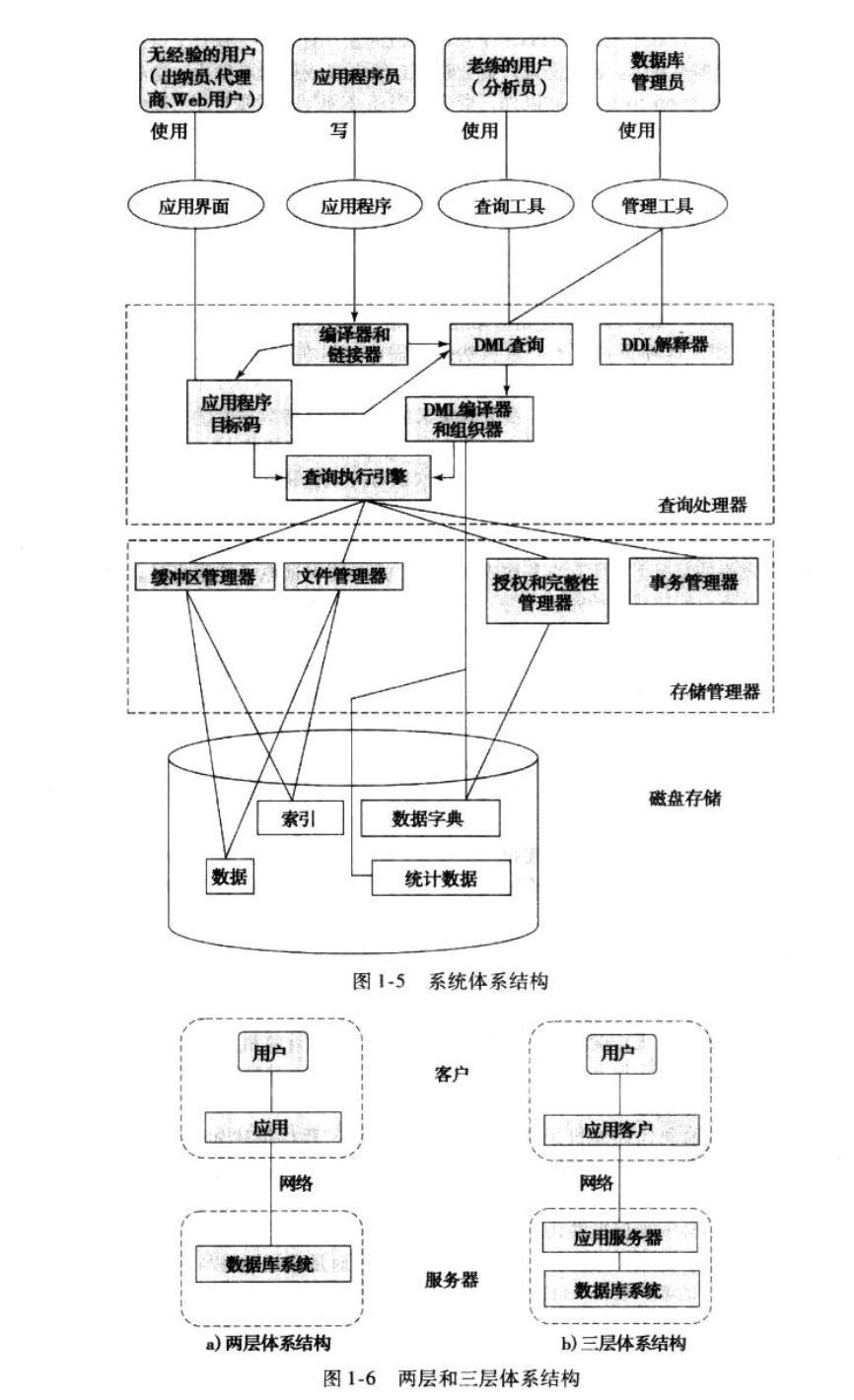
存储管理器是数据库系统中负责在数据库中存储的低层数据与应用程序以及向系统提交的查询之间提供接口的部件。存储管理器负责与文件管理器交互。原始数据通过操作系统提供的文件系统存储在磁盘上。存储管理器将各种DML语句翻译为底层文件系统命令。
存储管理部件:
- 权限及完整性管理器(authorization and integrity manager),它检测是否满足完整性约束,并检查试图访问数据的用户的权限。
- 事务管理器(transaction manager),它保证即使发生了故障,数据库也保持在一致的状态,并保证并发事务的执行不发生冲突。
- 文件管理器(file manager),它管理磁盘存储空间的分配,管理用于表示磁盘上所存储信息的数据结构。
- 缓冲区管理器(buffer manager),它负责将数据从磁盘取到内存中来,并决定你哪些数据应被缓冲存储在内存中。缓冲区管理器 是数据库系统中的一个关键部分,因为它使用数据库可以处理比内存更大的数据。
存储管理器实现了集中数据结构:
- 数据文件(data files),存储数据库自身。
- 数据字典(data dictionary),存储关于数据库结构的元数据,尤其是数据库模式。
- 索引(index),提供对数据项的快速访问。
查询处理器:
- DDL解释器(DDL interpreter),它解释DDL语句并将这些定义记录在数据字典中。
- DML编译器(DML compiler),将查询语言中的 DML语句翻译为一个执行方案,包括一系列查询执行引擎能理解的低级指令。
一个查询通常可被翻译为多种等价的具有相同结果的执行方案的一种。DML编译器还进行查询优化(query optimization),也就是从几种选择中选出代价最小的一种。
- 查询执行引擎(query evaluation engine),执行由DML编译器产生的低级指令。
5. 事务管理
事务(transaction)是数据库应用中完成单一逻辑功能的操作集合。每一个事务是一个既具有原子性又具有一致性的单元。
事务管理器(transaction manager)包括并发控制管理器和恢复管理器。
并发管理器(concurrency-control manager)控制并发事务间的相互影响,保证数据库一致性。
恢复管理器(recovery manager)负责保证原子性和持久性。
6. 数据库体系结构
数据库应用通常可分为两或三个部分。
7. 数据挖掘和信息检索
数据挖掘(data mining)这个术语指半自动地分析大型数据库并从中找出有用的模式的过程。
SQL基础
1. SQL查询语言预览
- 数据定义语言 (Data-Definition Language, DDL):SQL DDL提供定义关系模式、删除关系以及修改关系模式的命令。
- 数据操作语言(Data-Manipulation Language, DML):SQL DML提供从数据库中查询信息,以及 在数据库中插入元组、删除元组、修改元组的能力。
- 完整性(integrity):SQL DDL包括定义完整性约束的命令,保存在数据库中的数据必须满足所定义的完整性约束。破坏完整性约束的更新是不允许的。
- 视图定义 (view definition):SQL DDL包括定义视图的命令。
- 事务控制(transaction control):SQL 包括定义事务的开始和结束的命令。
- 嵌入式SQL和动态SQL(embedded SQL and dynamic SQL):嵌入式和动态SQL定义SQL语句如何嵌入到通用编程语言,如C、C++和Java中。
- 授权(authorization):SQL DDL包括定义对关系和视图的访问权限的命令。
1.1 SQL数据定义
基本类型:
- char(n):固定长度的字符串,用户指定长度n。也可以使用全称character。
- varchar(n):可变长度的字符串,用户指定最大长度n,等价于全称character varying。
- int:整数类型,等价于integer。
- smallint:小整数类型。
- numeric(p,d):定点数,精度由用户指定。
- real,double precision:浮点数与双精度浮点数,精度与机器相关。
- float(n):精度至少为n位的浮点数。
索引
两种基本的索引类型:
- 顺序索引。基于值的顺序排序。
- 散列索引。介于将值平均分不到若干散列桶中。一个值所属的散列桶是由一个函数决定的,该函数称为散列函数。
对于索引的考虑因素:
- 访问类型(access type):能有效支持的访问类型。访问类型可以包括找到具有特定属性值的记录,以及找到属性值落在某个特定范围内的记录。
- 访问时间(access time):在查询中使用该技术找到一个特定数据项货数据项集所需的时间。
- 插入时间(insertion time):插入一个新数据项所需的时间。该值包括找到待删除项所需的时间,以及更新索引结构所需的时间。
- 空间开销(space overhead):索引结构所占用的额外存储空间。
1. 顺序索引
顺序索引按照顺序存储搜索码的值,并将每个搜索码与包含该搜索码的记录关联起来。
被索引的文件中的记录自身也可以按照某种排序顺序存储,正如图书馆中的书按某些属性顺序存放一样。一个文件可以有多个索引,分别基于不同的搜索码。
如果包含记录的文件按照某个搜索码指定的顺序排序,那么该搜索码对应的索引称为聚集索引(clustering index)。聚集索引也称为 主索引(primary index);搜索码指定的顺序与文件中记录的物理顺序不同的索引称为非聚集索引(nonclustering index)或辅助索引(secondary index)。
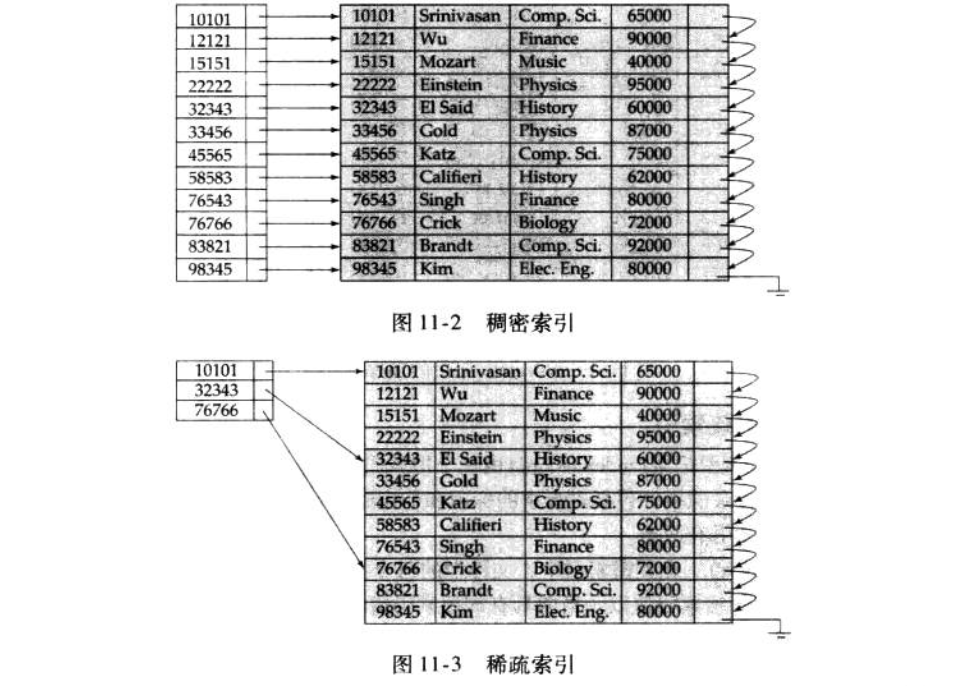
稠密索引和稀疏索引
索引项(index entry)或索引记录(index record)由一个搜索码值和指向具有该搜索码值的一条或者多条记录的指针构成。指向记录的指针包括磁盘块的标识和标识磁盘块内记录的块内偏移量。
可以使用的顺序索引有两类:
- 稠密索引(dense index):在稠密索引中,文件中的每个搜索码值都有一个索引项。在稠密索引中,索引项包括搜索码值以及指向具有该搜索码的第一条数据记录的指针。具有相同搜索码值的其余记录顺序的存储在第一条数据记录之后,由于该索引是聚集索引,因此记录根据相同的索引码值排序。在稠密非聚集索引中,索引必须存储指向所有具有相同搜索码值的记录的指针列表。
- 稀疏索引(sparse index):在稀疏索引中,只为搜索码的某些值建立索引项。只有当关系按搜索码排列顺序存储时才能使用稀疏索引,换句话说,只有索引是聚集索引时才能使用稀疏索引。和稠密索引一样,每个索引项也包括一个搜索码和指向具有该搜索码值的第一条记录的指针。为了定位一条记录,我们找到其最大搜索码值小于或等于所查找记录的搜索码值的索引项。然后从该索引项指向的记录开始,沿着文件的指针查找,直到找到记录为止。
多级索引
具有两级或者两级以上的索引称为多集(multilevel)索引。多级索引搜索记录于用二分法搜索记录相比需要的I/O操作要少得多。
- 本文链接: http://blog.programer.group/mysql/2019-12-05-database/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!