线程池
| 本文总阅读量次在生产环境中,应避免直接创建线程,线程数量必须得到控制。
1. 线程池
为了控制线程,JDK类库提供了一套Executor框架。
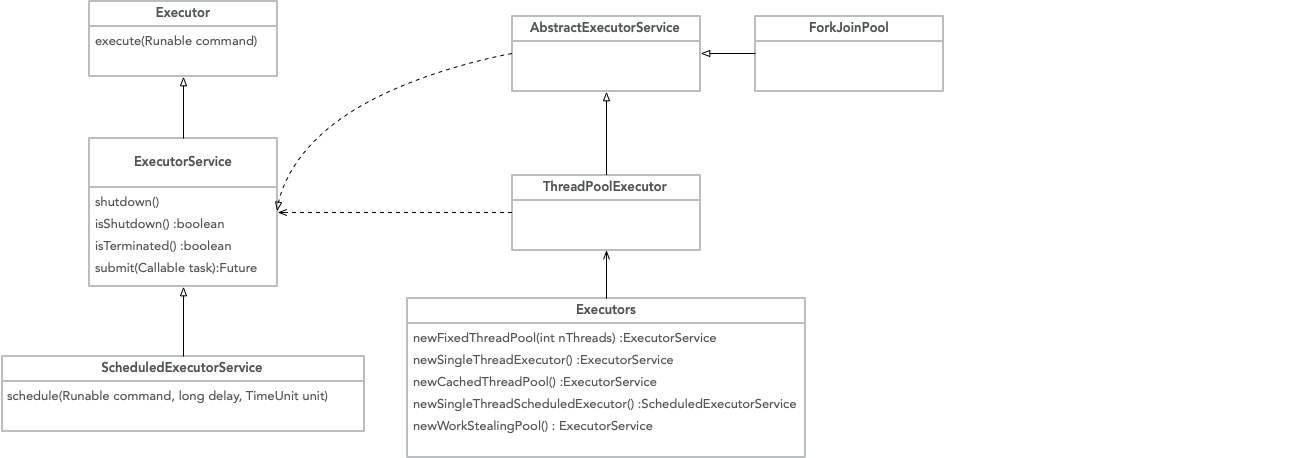
线程池是JDK用来管理线程的的静态工厂。上图中ThreadPoolExecutor表示一个线程池。
Executor是一个接口,接口中只有void execute(Runnable command)方法。
ExecutorService也是一个接口,继承ExecutorService,增加了许多使用线程池的公用方法定义。
AbstactExecutorService为ExecutorService接口提供了默认实现。
ThreadPoolExecutor继承AbstactExecutorService抽象类。
Executors类是JDK1.5版本时封装的线程池工厂和工具类,这个类提供了几种默认的线程池类型和默认线程池工厂。
ForkJoinPool是Java7加入的一种用于并行执行任务的框架
1.1 创建线程池
创建线程池的实现其实是实例化ThreadPoolExecutor的过程:1
2
3
4
5
6
7
8public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
}
corePoolSize:指定线程池中的线程数量。
maximumPoolSize:线程池中的最大线程数量。
keepAliveTime:当线程池超过corePoolSize时,多余的空闲线程的空闲时间。
unit:keepAliveTime的时间单位。
workQueue:任务队列,被提交但未被执行的任务。
threadFactory工厂:创建线程的工厂,一般默认就可以。
handler:拒绝策略,当线程池满负荷运行,如何拒绝新的任务的策略。
参数解析
keepAliveTime,unit,threadFactory几个参数可根据线程池的任务场景去做简单的变化,在此不再赘述,一般自定义线程池我们的关注点大都在corePoolSize,maximumPoolSize,workQueue,handler四个参数上。
corePoolSize,根据业务的通用场景确定即可。《Java并发编程实践》书中给出了一个估算线程池corePoolSize大小的经验公式:
Ncpu=cpu数量
Ucpu=希望cpu的使用率,0<Ucpu<1
W/C=等待时间与计算时间的比率, CPU计算时间计算方式
Nthreads=Ncpu*Ucpu*(1+W/C)
如果你处理的是阻塞比较多的任务,你可以根据上述公式大致算出需要的线程数量(一般会远远超出当前实例所在服务器的cpu数量);如果是阻塞比较少的任务即cpu计算比重较大的任务,线程的数量可能就会相应的减少一些,避免服务器的超负荷运行。总之线程数不是精确的一个数,只要符合你业务的场景的大概数量就可以。
workQueue任务队列分为有限、无限、同步移交三种阻塞队列,常用的有如下几个:
- ArrayBlockingQueue: 一个基于数组结构的有界阻塞队列,此队列按照FIFO原则排序。
- LinkedBlockingQueue: 一个基于链表的阻塞队列,此队列按照FIFO原则排序,吞吐量高于ArrayBlockingQueue。
- SynchronousQueue: 一个不存储元素的阻塞队列。每个插入操作必须阻塞到另一个线程的移除操作。
- PriorityBlockingQueue: 具有优先级的无限阻塞队列。
线程池的执行过程:
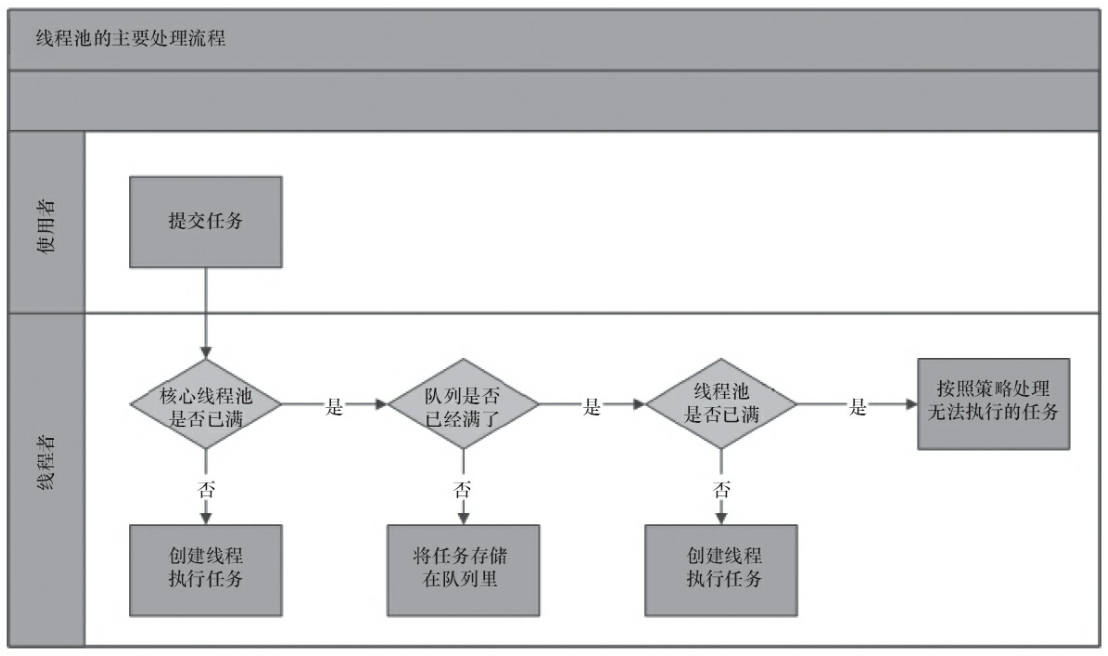
–图摘自《Java并发编程艺术》9.1小节-线程池的实现原理。
队列的大小和maxmumPoolSize息息相关,如果使用无界队列,则maxmumPoolSize也就失效了,如果使用的是有界队列,则当有界队列满了,则新启动线程执行任务。直到最大线程也满了之后执行拒绝策略。
最后就是拒绝策略:
- AbortPolicy: 直接抛出异常。
- CallerRunPolicy: 使用调用者的线程执行任务。
- DiscardOldestPolicy: 丢弃队列里最老的任务,并执行当前任务。
- DiscardPolicy: 不处理,丢弃。
除此之外还可以实现RejectExecutionHandler接口,自定义拒绝策略。
1.2 Executor提供的几种类型的线程池解析
- Executors.newFixedThreadPool(1);
Executors.newFixedThreadPool创建的线程池可以指定核心线程数,但是使用的是无界队列,如果是IO密集型任务,可能导致内存溢出。
- Executors.newSingleThreadExecutor();
Executors.newSingleThreadExecutor()创建一个线程的线程池,同样使用无界队列,和newFixedThreadPool的差别仅限于核心线程数。
- Executors.newCachedThreadPool();
Executors.newCachedThreadPool()创建的线程池是一个没有队列的存储任务的线程池,线程池最大数量为Integer.MAX_VALUE。所以这个线程池会一直创建新的线程执行任务,可能导致内存溢出。适用于中小数量级的任务,且任务非CPU密集型。
- Executors.newScheduledThreadPool(1, Executors.defaultThreadFactory());
Executors.newScheduledThreadPool(1, Executors.defaultThreadFactory())创建可以定时或延时执行任务的线程池,与Timer相比,具有更多的弹性。详解Java定时任务—极客学院
- Executors.newWorkStealingPool();
封装的ForkJoinPool线程池,线程数量为当前运行环境的cpu数量,不处理异常,异步模式。下一小节详细介绍。
1.3 ForkJoinPool线程池初探
Fork/Join框架是Java 7提供的一个用于并行执行任务的框架,是一个把大任务分割成小任务,最终汇总小任务结果后得到大任务结果的框架。
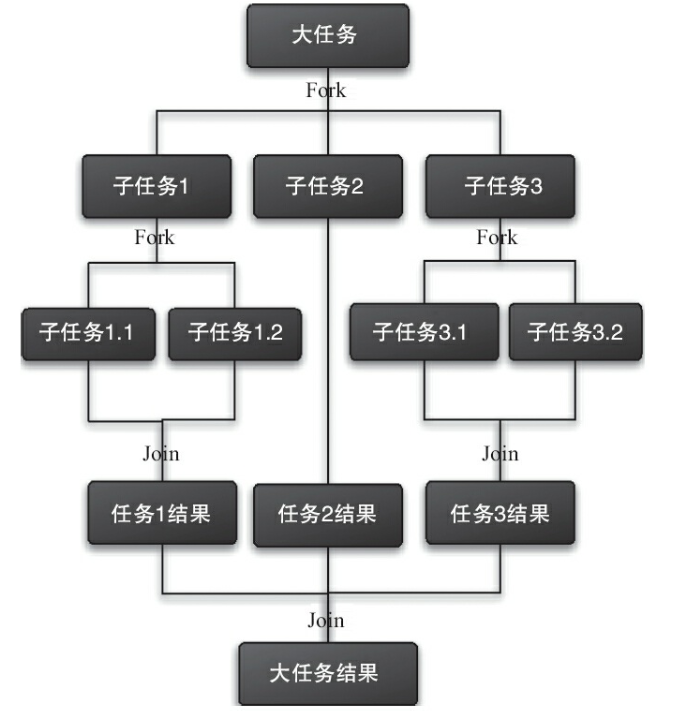
–图片摘自《Java并发编程的艺术》6.4.1 什么是Fork/Join框架 小节。
缺点:在某些情况下,该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。
使用ForkJoinPool
1 | private static final int THRESHOLD = 2; // 阈值 private int start; |
–示例摘自《Java并发编程的艺术》6.4.4 使用Fork/Join框架 小节。
异常处理
ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被 取消了,并且可以通过ForkJoinTask的getException方法获取异常。使用如下代码。1
2
3if(task.isCompletedAbnormally()) {
System.out.println(task.getException());
}
getException方法返回Throwable对象,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
原理解析
ForkJoinPool继承AbstractExecutorService。
ForkJoinPool参数:
- parallelism线程数量;
- ForkJoinWorkerThreadFactory是ForkJoin线程工厂,创建ForkJoinWorkerThread的线程类实例;
- mode是使用FIFO模式(true)还是LIFO模式(false);
- UncaughtExceptionHandler是异常处理;
- workerNamePrefix工作线程的名称前缀;
通常来说,我们使用ForkJoinPool时如果不指定线程数量时默认取2047和当前服务器cpu数量中的最小值。简单来说就是创建了一个fork/join线程的线程池。
参考资料
Effective Java 第二版 中文版
实战Java高并发程序设计 葛一鸣,郭超编著
Java并发编程艺术 方腾飞,魏鹏,程晓明 著
- 本文链接: http://blog.programer.group/concurrency/2019-11-07-threadpool/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!